Tuning Engines
Tuning Engines is the unified, governed runtime that secures, optimizes, and streamlines every AI interaction through one API.
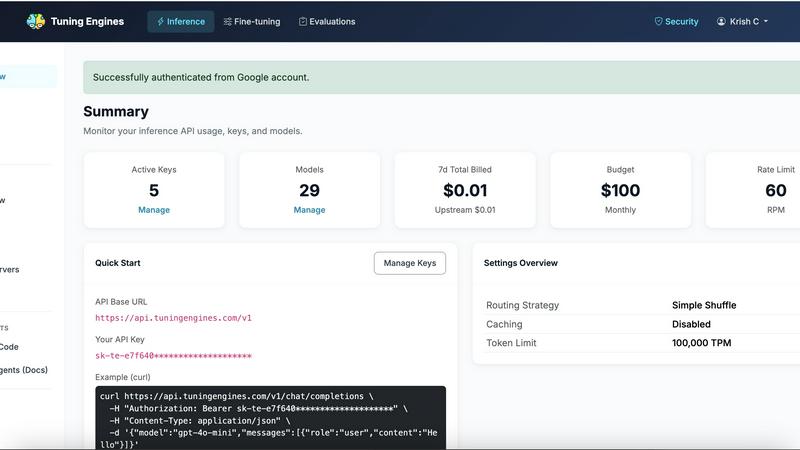
About Tuning Engines
Tuning Engines is a unified AI control and governance layer purpose-built for teams constructing production intelligence across models, agents, tools, and fine-tuned systems. Think of it as the operating system for your AI stack. Instead of juggling multiple providers, managing scattered API keys, and wrestling with inconsistent governance, Tuning Engines brings the entire AI lifecycle into one secure, observable, and extensible platform. It handles everything from inference and model routing to fallback policies, fine-tuning jobs, datasets, evaluations, model imports and exports, custom models, agents, MCP servers, reusable skills, guardrails, policy-as-code, data capture, runtime traces, usage analytics, API keys, billing, team roles, and integrations.
The magic is in the simplicity. Developers get a single OpenAI-compatible endpoint that unlocks over 100 models, including open models like Llama, DeepSeek, Qwen, and Mistral, plus frontier commercial models and your own tuned variants. You keep your existing SDK and just swap one base URL. Teams can seamlessly connect Claude Code, OpenCode, Aider, Cline, Roo, Continue.dev, Cursor, VS Code, Windsurf, and other AI workflows through this governed platform. For admins, it is a dream come true with role-based access, per-key budgets, rate limits, routing profiles, fallback rules, guardrails, policy-as-code, credential sources, full auditability, usage traces, billing controls, tenant isolation, and team management. Tuning Engines helps organizations move beyond isolated AI experiments into a secure, cost-aware, and scalable AI operating layer.
Features of Tuning Engines
Unified Inference
Access any model through one OpenAI-compatible API endpoint. Call open models like Llama 3.3 70B, DeepSeek V3, Qwen 2.5, or Mistral, plus commercial frontier models and your own fine-tuned variants, all from the same SDK. No code rewrites, no new clients to learn. Just swap your base URL and instantly unlock over 100 models with centralized policy, full auditability, and token controls applied to every single request.
Model Tuning and Lifecycle
Adapt open models to your specific data, language, and production goals. Run supervised fine-tuning and LoRA adapters directly on the platform without managing any GPU infrastructure. The model lifecycle is fully supported from building with one endpoint, to tuning with your data, to hosting and scaling your custom models. Evaluation gates ensure quality moves with your business requirements.
Policy-as-Code and Governance
Centralized guardrails, access controls, and full request traceability across every model interaction. Implement AGT YAML policies, set per-key budgets and rate limits, define routing profiles with fallback rules, and enforce tenant isolation. Every request is auditable with runtime traces, giving admins complete visibility and control over AI usage across the entire organization.
Token Economics and Cost Management
Infrastructure costs are passed through at-cost with zero markup. You only pay for support and platform upkeep. Set cost ceilings, quotas, and routing policies so spend and rate limits stay predictable. Track usage analytics per team, per key, and per model. This design ensures your AI operations are not only powerful but also financially sustainable and transparent.
Use Cases of Tuning Engines
Code Assistance and IDE Copilots
Power your development workflows with AI copilots for code generation, refactoring, and debugging. Connect Claude Code, OpenCode, Aider, Cline, Roo, Continue.dev, Cursor, VS Code, or Windsurf to Tuning Engines. Developers get governed access to the best models for code tasks, with centralized policy controls ensuring compliance and cost management across the entire engineering team.
Conversational AI and Customer Support
Build customer support bots, internal helpdesks, and multilingual chat systems that are secure, scalable, and cost-aware. Use the unified API to route conversations to the most appropriate model based on complexity, cost, or latency requirements. Fallback policies ensure uptime, while guardrails and audit trails maintain safety and compliance in every customer interaction.
Agentic Systems and Multi-Step Reasoning
Deploy multi-step reasoning, planning, and tool-using execution pipelines with full governance. Tuning Engines provides MCP servers, reusable skills, and agent integration capabilities. Admins can set per-agent budgets and rate limits while developers access the exact models and tools needed. Runtime traces provide observability into every decision an agent makes.
Enterprise RAG and Knowledge Retrieval
Implement secure, scalable retrieval over knowledge bases and private documents. Use the embedding models available in the model library to power semantic search. Combine retrieval with LLMs for enterprise assistants that provide accurate, context-aware answers. Centralized policy ensures that sensitive data remains protected while still enabling powerful AI-driven knowledge discovery.
Frequently Asked Questions
What models are available on Tuning Engines?
The platform offers over 100 models through a single OpenAI-compatible endpoint. This includes open models like Llama 3.3 70B, Llama 3.1 8B, DeepSeek V3, DeepSeek R1, Qwen 2.5 72B, Qwen 2.5 Coder 32B, Mistral Small 3, Mixtral 8x7B, Gemma 2 27B, Llama 3.2 Vision, Whisper Large v3, and embeddings from the BGE/E5 family. You also get access to commercial frontier models and any model you fine-tune on the platform.
How does pricing work for Tuning Engines?
Tuning Engines is designed with a transparent cost model. Infrastructure costs for inference and compute are passed through at-cost with zero markup. You only pay for the platform support and upkeep. This means you get the best possible pricing on model inference while benefiting from centralized governance, auditability, and management features. You can also set cost ceilings, quotas, and routing policies to keep spend predictable.
Can I use my existing SDK and code with Tuning Engines?
Yes, absolutely. Tuning Engines provides a drop-in OpenAI-compatible endpoint. You keep your existing OpenAI SDK and simply change the base URL to https://api.tuningengines.com/v1. No code rewrites, no new client libraries to learn. Your existing code for chat completions, embeddings, and other API calls will work immediately with full governance and policy controls applied automatically.
How does Tuning Engines handle governance and security?
Governance is built into every layer. Admins can define role-based access controls, per-key budgets, rate limits, routing profiles, fallback rules, and guardrails using policy-as-code with AGT YAML. Every request is captured with runtime traces for full auditability. The platform provides tenant isolation, credential source management, and team management. This ensures that even as you scale AI across your organization, you maintain complete control and visibility.
Top Alternatives to Tuning Engines
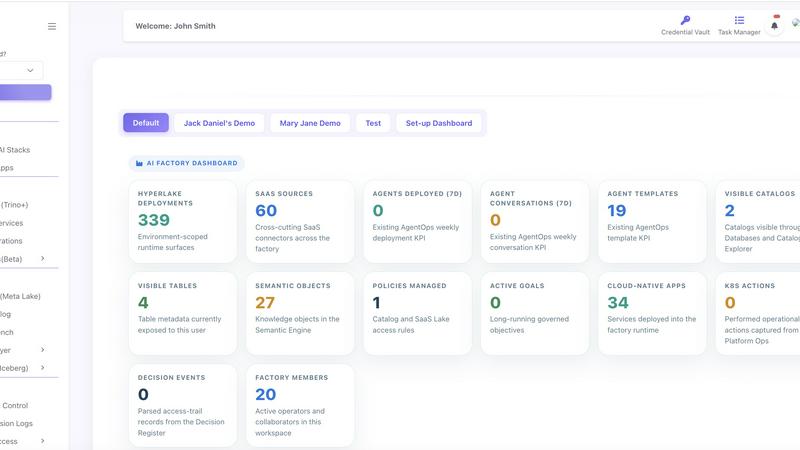
HyperLake
HyperLake is the sovereign AI factory that provisions governed, agentic infrastructure in your cloud with zero compute markup.
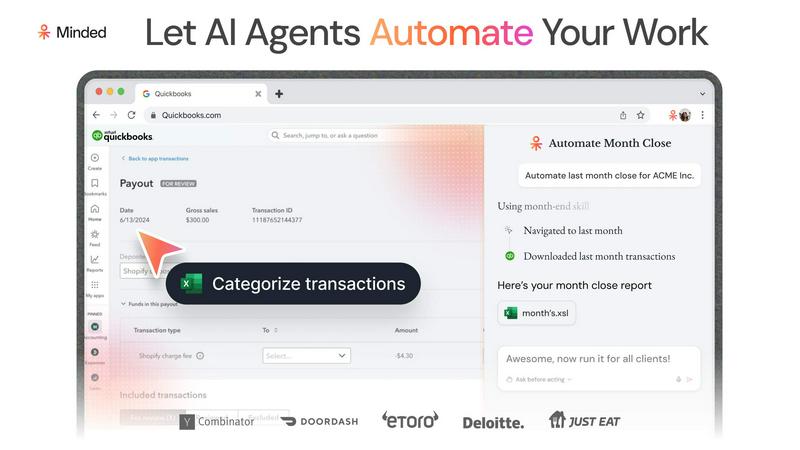
Minded
Minded lets you effortlessly build AI agents that handle tasks efficiently, transforming your workflow and delighting customers from day one.
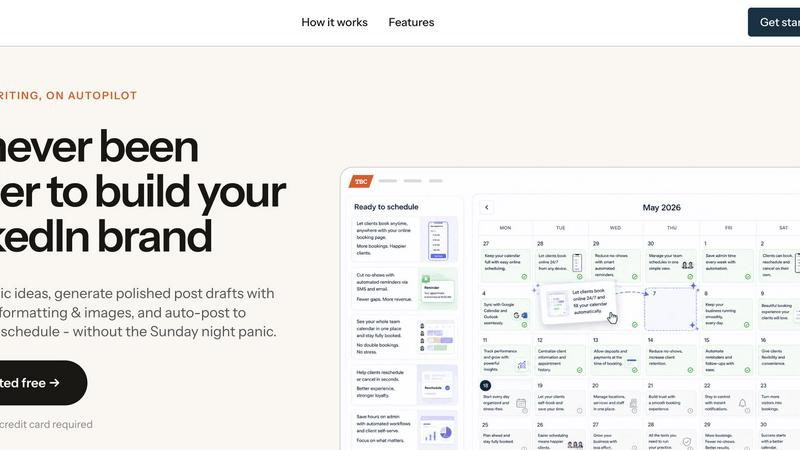
TBC
TBC automates your LinkedIn posting with AI drafts, rich formatting, and scheduled publishing so you build your brand effortlessly.

Hyring
Hyring's AI recruiting platform helps you hire more humans by automating screenings, interviews, and candidate ranking.

InstantDM
InstantDM automates your Instagram DMs and comments, turning followers into customers effortlessly for just $9.99 a month.

YCaaS
YCaaS delivers recursive AI execution on demand, letting you iterate and scale complex workflows instantly without infrastructure limits.

AgentZee
AgentZee empowers businesses to effortlessly create AI agents for sales, support, and marketing automation that work seamlessly together.
xyOps
xyOps is the all-in-one workflow automation platform that orchestrates your entire infrastructure with scheduling, monitoring, and alerting built in.